projects
This portfolio highlights selected projects from my research and industry work. The focus is on multimodal learning, scientific AI, perception, and human-centered systems. Several projects from professional roles cannot be shared due to IP restrictions, but representative public work is included below.
The goal here is to show a small set of projects that best reflects the direction of my current work.
Foundation Vision-Language Model for Materials Science & Material Discovery
Feb 2024: Some of the post-training and ablation-driven insights from this project have been published as a preprint, together with a benchmark for materials VLMs. (arXiv) — 🤗 Model — 🤗 Dataset
I worked on a domain-specialized vision–language foundation model for materials science, designed to support automated captioning, general material science understanding, hypothesis generation with literature-grounded reasoning, and the generation of novel material compositions(including conditional generation for properties like ductility). The project combines large-scale multimodal pretraining with continual domain adaptation to bridge the gap between general-purpose VLMs and highly technical scientific data.
A major component of my work involves continual pretraining on a curated corpus of materials-science literature, microscopy images, crystal structures, synthesis descriptions, and property tables. To support efficient scaling, I built distributed training pipelines with DeepSpeed, activation checkpointing, and sharded GPU memory, enabling training across multiple GPUs while maintaining stability over long-horizon runs.
I implemented multimodal alignment modules that combine vision encoders (SEM images, XRD patterns, microscopy) with text encoders trained on domain-specific terminology. The system incorporates contrastive pretraining, masked modality modeling, and mixture-of-experts routing to integrate disparate scientific formats.
On the evaluation side, I also designed benchmarking tasks to measure the model’s ability to:
- Generate composition or structure-aware captions for Scanning Electron Microscopy (SEM) & X-Ray Diffraction (XRD) images
- Perform hypothesis generation with property-aware reasoning with literature-derived descriptors
- Answer PhD-level materials science reasoning questions
- Propose novel hypothetical materials satisfying target conditions (e.g., band gap, yield strength...)
The model can then be used to generate material candidates that we can then experimentally test in our autonomous lab. This creates a unique closed-loop system in which synthesized results can be reincorporated into training via continual finetuning, which tighten the model’s alignment to real physical behavior instead of purely simulated data.
Looking ahead, as the model is increasingly integrated into the lab workflow, I am excited to leverage the closed-loop data it produces to apply reinforcement learning from human and experimental feedback, that will allow continual improvement of generative material proposals.
Pet Robot: Cognitive Architecture for Affective Human–Robot Interaction
At Konpanion, our pet robot Maah was created to address loneliness among older adults in care homes. I served as the applied researcher responsible for developing the robot’s cognitive architecture, perception pipeline, and adaptive behaviour models.
My work drew on research in human–robot interaction, animal behaviour, cognitive architectures, multimodal perception, and agent design. The central question was how to design a robot that behaves like a real animal: emotionally responsive, socially aware, and capable of forming long-term attachments.
I designed a stateful cognitive architecture that integrates vision, audio, tactile and motion sensing with reinforcement-learning–based planning. This enabled the robot to maintain internal variables such as affect, arousal, memory, preferences, social bond strength and environmental context. These internal representations allowed the robot to make decisions that evolve over time instead of relying on scripted behaviours.
Understanding the user was a key challenge. I developed a multimodal emotion recognition system using speech and facial cues, achieving 89% accuracy in real-world deployment. These estimates informed behaviour selection and provided caregivers with interpretable summaries of user emotional state.
I also explored how the robot’s behaviour could change with experience. The system incorporated long-term memory, reinforcement-based behavioural shaping and experience-driven emotional responses so that each robot developed a unique interaction style over time, similar to how real companion animals form bonds with their owners.
The visual design of Maah was intentionally non-anthropomorphic to make the robot feel comforting, safe and approachable for vulnerable users in care environments.

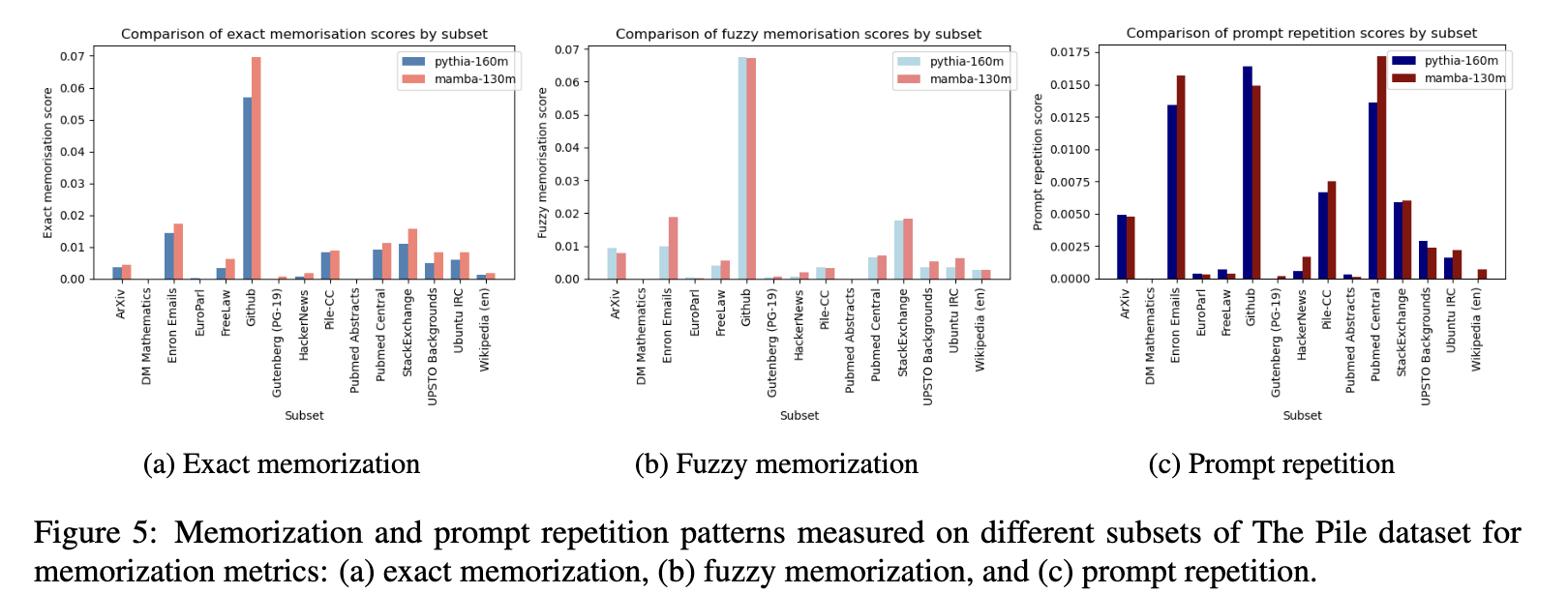
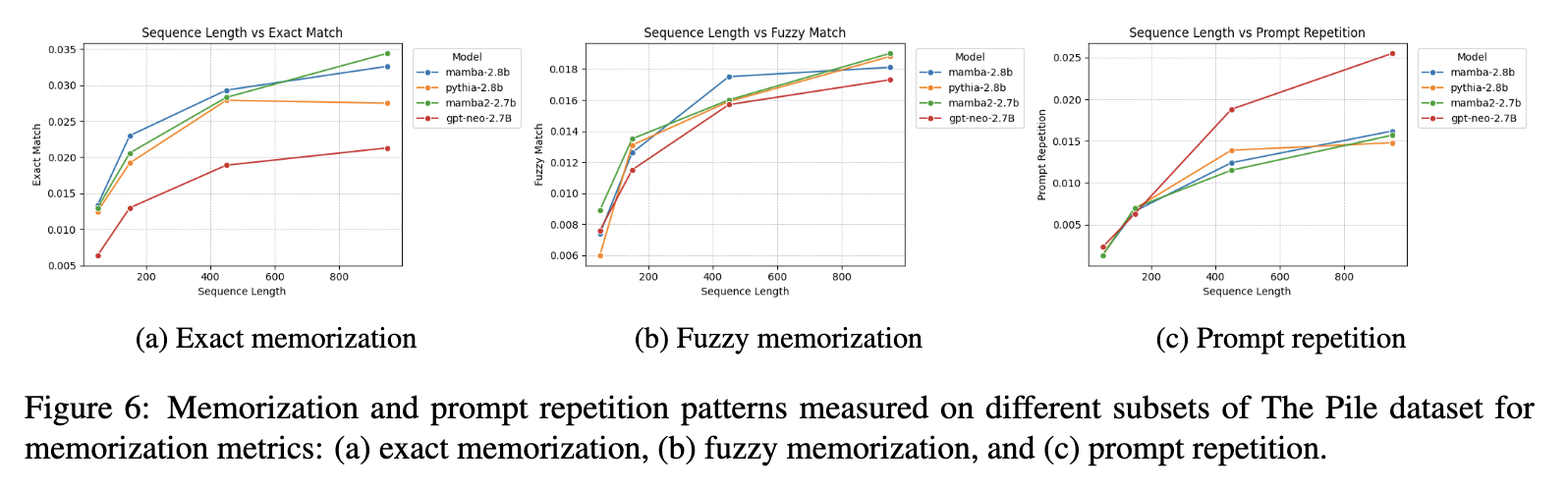
LLM Extraction Attacks on State Space Models & Transformers
This project examines how different LLM architectures memorize and leak training data by evaluating both state space models (SSMs) and transformers under extraction attacks. The goal was to understand how their architectural inductive biases influence what information is stored and how easily it can be recovered.
I implemented two complementary evaluation settings: a standard data extraction attack and a leakage attack based on in-context learning, where private information is placed in demonstrations and later recovered by strategic prompting. These setups allowed me to isolate how each architecture handles rare sequences, unique identifiers, and structured sensitive patterns.
Across scaling experiments, I found that SSM-based LLMs match transformers on downstream performance but consistently exhibit higher rates of memorization under both extraction and ICL-based leakage attacks. The results suggest that recurrence and architectural memory in SSMs cause different retention behaviours compared to the attention-based mechanisms in transformers.
ESCAILATOR — Emotional Sensing Chatbot & Lingual AI Therapy
As part of the EU-funded ESCAILATOR initiative, I worked on developing an emotional sensing chatbot and language-based therapeutic assistant for breast cancer patients. My research motivation was to investigate how linguistic and acoustic features can serve as signals for emotional state, psychological distress, and patient well-being.
I integrated speech emotion recognition, linguistic biomarkers, and adaptive conversational strategies into a unified system aimed at supporting remote psychological assessment. The system was designed to encourage honest self-reporting through natural conversation rather than structured questionnaires.
I explored how affective signals and language patterns correlate with clinical indicators, and how these signals can be incorporated into models that remain interpretable for clinicians. This contributed to broader research questions in affective computing, mental health monitoring, and designing empathetic human–AI interactions.
Pixel Mamba — State Space Architecture for Vision-Language Pre-training
Pixel Mamba explores how state space models (SSMs) can replace transformer blocks in vision–language pretraining. The research question was whether architectural differences in sequence modeling would affect efficiency, stability, and downstream performance on multimodal tasks.
I rearchitected the PIXEL model by substituting transformer layers with Mamba-based SSM layers, then implemented and trained the modified model on masked language modeling and GLUE tasks. The SSM variant achieved 2.8× faster processing and an 86.8% reduction in GPU memory usage while maintaining competitive accuracy.
This project deepened my understanding of long-range sequence modeling, architectural inductive biases, and the trade-offs between efficiency and representational capacity. It also informed my later work on memorization and extraction attacks, where SSMs show distinct retention characteristics compared with transformers.
Multimodal Migraine Tracking & Prediction
This project investigated how multimodal signals can be combined to predict migraine onset in a personalized way. The research motivation was to understand how physiological data and naturalistic speech can be fused to model patterns that vary significantly across individuals.
I built a pipeline that integrates embedded sensor data (e.g., activity, heart rate), environmental context, and spoken diary entries into a unified representation. I explored both user-independent and personalized modeling strategies to handle high inter-individual variability.
Through evaluation, I analyzed how much data was needed per user before personalization improved performance, and which modalities contributed most to predictive accuracy. This work strengthened my interest in multimodal sequence modeling, personalization under data scarcity, and health-oriented AI systems.
Vision State Estimation for Arc Melting
Under review.
Co-first author.
Arc melting is the principal process for synthesising refractory alloys, but it remains almost entirely manual. The chamber has no external lighting: all illumination comes from the arc, which saturates the camera, flickers with current, and is blocked by the torch during operation. Standard foundation models fail completely in this regime.
A perception and state estimation pipeline was developed for this environment, using nnU-Net and SAM 2 as a non-causal teacher to generate training labels, then distilling to a lightweight causal student with a ConvGRU for temporal context. The segmentation output feeds a melt-progress estimator and a time-to-completion predictor, giving a stable scalar signal suitable for closed-loop robotic control.
